How the browser renders a web page? (I)
Information drawn from
Document Object Model (DOM)
When the browser reads HTML code, whenever it encounters an HTML element like html, body, div etc., it creates a JavaScript object called as Node. **Eventually, **all HTML elements will be converted to JavaScript objects. Since every different HTML element has different properties, the Node object will be created from different classes (constructor functions).
For example, the Node object for the div element is created from HTMLDivElement which inherits Node class. The browser comes with built-in classes like HTMLDivElement, HTMLScriptElement, Node etc.
After the browser has created Nodes from the HTML document, it has to create a tree-like structure of these node objects. Since our HTML element will be nested inside each other, browser needs to replicate that but using Node objects it has previously created. This will help the browser efficiently render and manage the webpage through its lifecycle.
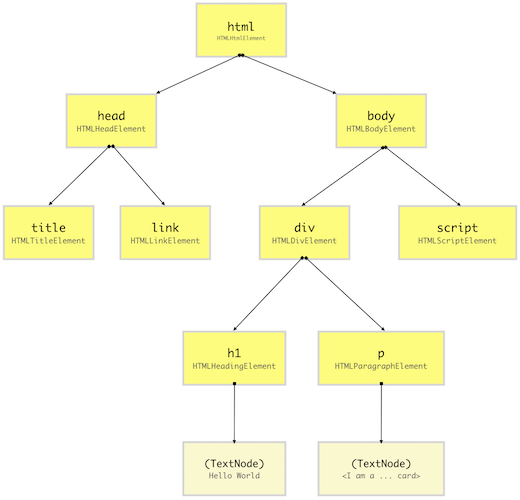
A DOM node doesn’t always have to be an HTML element. When the browser creates a DOM tree, it also saved things like comments, attributes, text as separate nodes in the tree. But for the simplicity, we will just consider DOM nodes for HTML elements AKA DOM element. Here is the list of all DOM node types
JavaScript doesn’t understand what DOM is, it is not part of the JavaScript specifications. DOM is a high-level Web API provided by the browser to efficiently render a webpage and expose it publically for the developer to dynamically manipulate DOM elements for various purposes.
Using DOM API, developers can add or remove HTML elements, change its appearance or bind event listeners. Using DOM API, HTML elements can be created or cloned in memory and maniuplated without affecting the rendered DOM tree. This gives developers the ability to construct highly dynamic web page with rich user experience.
CSS Object Model (CSSOM)
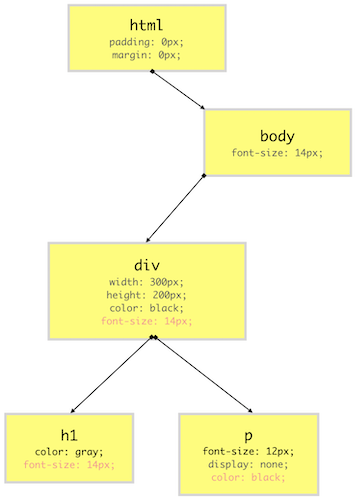
After constructing the DOM, the browser reads CSS from all the sources (external, embedded, inline, user-agent, etc.) and construct a CSSOM. CSSOM stands for CSS Object Model which is a Tree Like structure just like DOM.
Each node in this tree contains CSS style information for that particular DOM element. CSSOM, however, does not contain DOM elements which can’t be printed on the screen like <meta>, <script>, <title> etc.
As we know, most of the browser comes with its own stylesheet which is called as user agent stylesheet, the browser first computes final CSS properties for DOM element by overriding user agent styles with CSS provided by the developer properties (using specificity rules) and then construct a node.
Even if a CSS property for a particular HTML element isn’t defined by either the developer or the browser, its value is set to the default value of that property as specified by W3C CSS standard. While selecting the default value of a CSS property, some rules of inheritance are used if a property qualifies for the inheritance as mentioned in the W3C documentation.
For example, color and font-size among others inherits the value of the parent if these properties are missing an HTML element. So you can imagine having these properties on an HTML element and all its children inheriting it. This is called as cascading of styles and that’s why CSS is called as Cascading Style Sheet. This is the very reason why the browser constructs a CSSOM, a tree-like structure to compute styles based on CSS cascading rules.
------------------------------------------------------------------------
Last update on 23 Feb 2020
---